




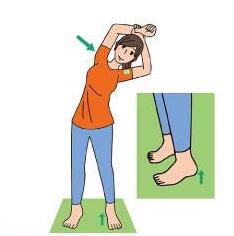













微信隐藏好友的方法: 一、首先打开微信APP,点击“通讯录”图标进入到通讯录界面。 二、在通讯录中查找要隐藏的好友,然后点击他头像或者昵称旁的小三角图标。 三、将会弹出一个框,里面有多项功能供你使用,此时你要点击“加入黑名单”这一项。 四、之后会有一个弹框询问是否真的想要将对方加入到你的黑名单中去?请再三考虑并作出决定。 五、如果决定将对方加入到你的微信好友中去,此时请直接点击 “OK” 或者 “ 立即屏 蔽 ” 此时这个人已经不存在于你的微信上了 (也就是隐 藏 其操作成功 ) 。

如果想要实现tokens数量大幅度减少而又能够保证对话性能不变化甚至有所增强呢? 首先,我们必须理解tokenization文本流表愿.Tokenization(文本流表)是将文章或文字分割成独立物件(token)来表愿.例如,一个常用tokenizer会选择"word","sentence","paragraph"来作为独立物件把整部文章分割.

考虑相似性: 由于tokens代表性太低,回避tokens数量大幅度增加常常使用N-grams来代表client/server side conversation context (i.e., sentence or paragraph level). N-grams are adjacent words that can be used to represent a phrase of text or a sentence in order for us to better understand the meaning behind each token and how they interact with each other within the same context. This allows us to reduce tokens while still preserving the quality of conversations by leveraging similarity between different phrases or sentences in order to identify similar topics being discussed, as well as different contexts where those same topics might appear. For example, we could replace all occurrences of "I love you" with an N-gram such as "love_you", allowing us to reduce our total number of tokens while still communicating the same message clearly and effectively.
最大化reuse: 各context之间存在相似性; 回避tokens数量大幅度增加也可以考���reusing existing tokens across different contexts instead of generating new ones every time there is a slight change in conversation topic or style (i.e., using synonyms). Reusing existing tokens also allows us to maintain consistency across conversations and eliminates redundancy when it comes to storing information about individual conversations on both client and server sides since we no longer need separate storage spaces for each unique token generated during any given conversation session - this helps further minimize memory usage while increasing overall system performance at the same time!
